
In today’s world, the cloud dominates most of what we access online. Rarely are websites still hosted on a single server in a single location. Most of the time, software is written with clustering and cloud in mind.
Developing clustered web based systems requires some unique thinking about architecture and synchronization. In this post I’d like to outline a project I have written in summer 2018 to achieve automatic recovery for a clustered system when one of it’s components blacks out.
The source code can be accessed on my github here. As noted in the readme over there, sadly the code pertaining to Kafka and ZooKeeper never made it to the project and as such it is incomplete. However, the general architectural idea of the project should still come through.
The system is implemented in go and sets up a back end, from now on called consumer. Whenever a client makes a request to this consumer, JavaScript code will be sent to the client effectively handling the client side code for refreshing the data. Data comes from a producer, which simply produces incrementing numbers, and sends them to the consumer. The client will periodically query the consumer for the changed data set.
Let’s take a look at the most basic implementation possible for the current system.

Here we can very obviously see that a blackout of the consumer will mean a blackout of the whole system. The only solution to recovery is to restart the system, restart the producers, and have clients make new requests. This is not great, but can be improved.
We could use Docker to set up multiple instances of this system like so.

However, a client will still have to manually redirect their requests in this scenario in the case a consumer blacks out. Additionally, any data stored within the consumers is not synchronized, so a client will lose the environment it previously had.
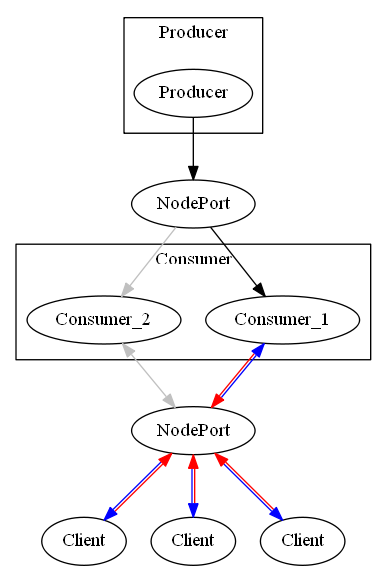
We can introduce Kubernetes and utilize the shared external address configured when using load balancing or node port. The resulting system might look something like this.

The client won’t notice if a consumer blacks out now, as kubernetes will redirect requests made to functioning pods internally. But, the diagram is a cheat. With multiple producers, we will reintroduce major synchronicity problems. And we will seldom have one singular data source in the real world, so let’s go back and revise this problem some more.
The immediate solution might be to introduce a common access point for all producers too. On paper this might look fine. However, we must keep in mind that the system might have an asychronous life cycle. What happens when one consumer dies somewhere during the execution of the system, and a new pod is created in it’s place? The data previously available to the consumer died with the pod, so the new consumer has less data available than the other consumers that have been alive for longer. Essentially, the synchronicity problem is something we can’t quite easily solve with these systems in use alone.
Luckily, theres Apache Kafka. Apache Kafka is essentially a message broker. You can query Kafka on the fly and avoid parking data for a limited time (which is enough for this example).
Using Kafka, we can envision a system like this.
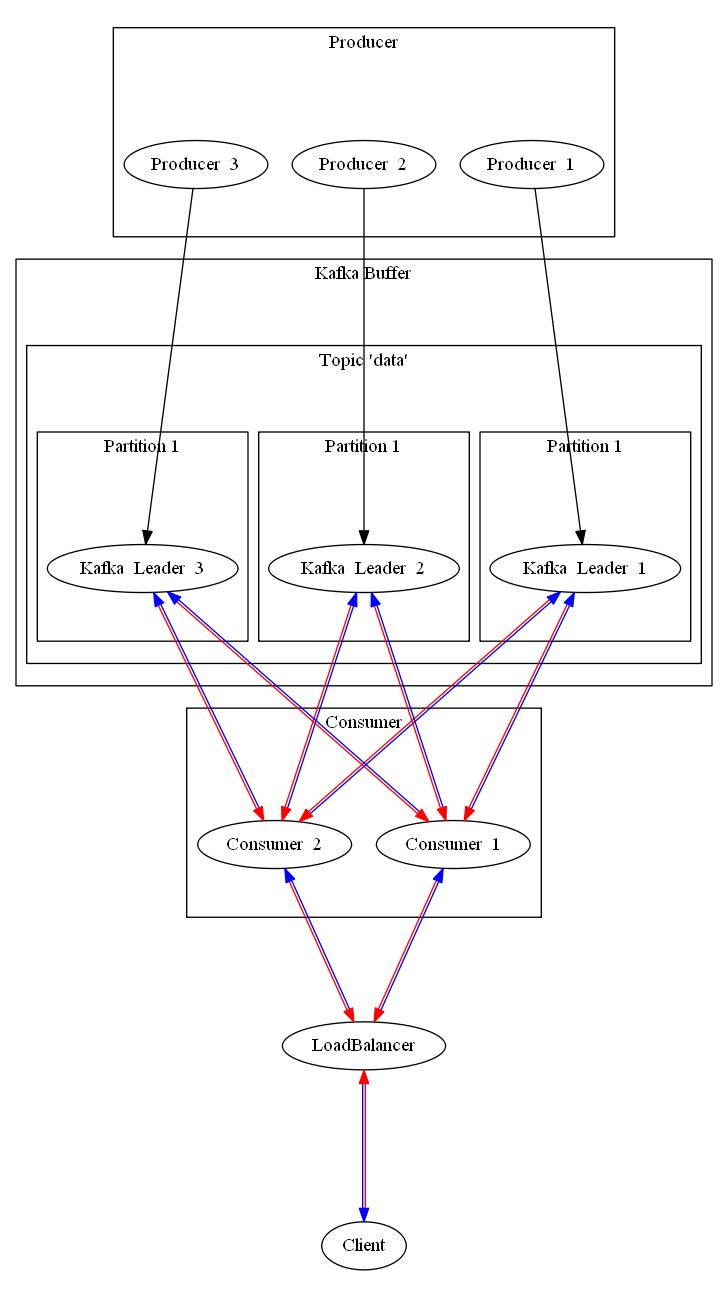
This is a complete system that has a buffer system provided by Kafka, self synchronizing all data that is provided to it. We don’t need to worry about failover for the Kafka system as long as we provide at least 3 pods at any one time for the Kafka system. It will handle leader election and synchronizing all by itself.
The clients still won’t notice a consumer black out as long as there is one consumer remaining, because kubernetes will redirect the calls internally on the fly. The clients will also not notice changes in environment, as all the data is queried from Kafka, which, as previously stated, self synchronizes.
It is fun trying to design a resistant and hardened clustered system, but a lot of things have to be taken into consideration to make sure it works.
Please make sure to build the project yourself (at least the docker version) and test it out!